 構造体とは何ぞや
構造体とは何ぞや| ← Prev (05) |
前回は、変数名の重複の問題に対処する方法として、 ローカル変数と変数宣言がプログラミング言語に 組み込まれたことを説明しました。 今回は、変数名によるデータ・アクセスではなく、 構造体を使ったアクセスがどのように有効だから、 プログラミング言語に 組み込まれたかについて説明します。
構造体とは何ぞやC 言語の勉強して、つまづくところといえば、 構造体とポインタが定番ですね。ポインタについては次回行うとして、 今回は、構造体について説明します。
『構造体とは、複数の変数をまとめるものである。』
よくある構造体の説明ですが、分かったようで分からない
説明だと思いませんか?
私が初めてその説明を聞いたとき、
「集めてどないすんねん。よけい面倒やないか。」という感想でした。
なぜ、そう思ったかについて、次の例を見てみましょう。
構造体の使用例のよくあるやつです。
/* 構造体の定義 */
struct st {
int a; /* メンバ変数 a */
char* b; /* メンバ変数 b */
};
/* メイン関数 */
void main()
{
struct st x; /* 構造体変数の宣言 */
x.a = getNum(); /* メンバ変数に代入するとき */
x.b = getStr();
printf( "%d", x.a ); /* メンバ変数を参照するとき */
printf( "%s", x.b );
}
|
ほうほう。a や b の変数を中に持った struct st が 構造体なんだな。x は、えーと、構造体の変数かな。 ってのが分かりますね。 しかし、よく考えてください。わざわざ構造体にまとめなくても 次のようにすれば済むじゃないですか。
void main()
{
int a; /* メンバ変数に相当する変数を使う */
char* b;
a = getNum();
b = getStr();
printf( "%d", a );
printf( "%s", b );
}
|
おー、できるできる。それなら、 構造体はよく分からんから、なるべく使わないようにしよう。 と思うのが普通だと思います。 しかし、そう思うのは、構造体の文法の説明されているからであって、 構造体を使うメリットが説明されていないからです。
では、構造体を使うメリットとは何でしょうか? まず考えられるのは、同じ構造(メンバ変数の構造)を 持った変数が簡単にたくさん作れることです。
/* 構造体の定義 */
struct st {
int a; /* メンバ変数 a */
char* b; /* メンバ変数 b */
int c;
int d;
};
/* メイン関数 */
void main()
{
struct st x; /* 構造体変数の宣言 */
struct st y; /* 構造体変数の宣言 */
struct st z[10]; /* 構造体配列の宣言 */
}
|
構造体を使わないと、次のように変数宣言が 大量に必要になります。しかも、パターンが見られるので、 何度もやっているとワンパターンになり、 退屈な労働をされている気分になります。
/* メイン関数 */
void main()
{
int x_a;
char* x_b;
int x_c;
int x_d;
int y_a;
char* y_b;
int y_c;
int y_d;
int z_a[10];
char* z_b[10];
int z_c[10];
int z_d[10];
}
|
他のメリットとして、関数の引数の数を減らせるという メリットがあります。
void func( struct st* x );
void func2( int a, char* b, int c, int d );
void main()
{
struct st x;
x.a = 10;
x.b = "aaa";
x.c = 12;
x.d = 21;
func( &x ); /* 構造体を使った引数 */
func2( x.a, x.b, x.c, x.d ); /* 構造体を使わない引数 */
}
|
関数の引数の数を減らすと、それだけ実行速度も速くなります。
なぜなら、CPU は、引数を1つ1つスタックやレジスタに
格納してから関数を呼び出しているからです。
構造体のメンバ変数へのアクセスの仕組み単純な変数と構造体では、CPU がメモリにアクセスする方法が 異なります。
単純な変数の場合、本コラム・第4回で説明したように 特定のメモリ領域を変数に割り当てています。
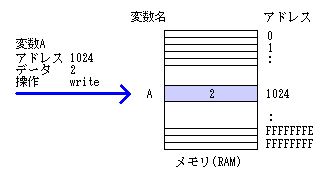
構造体の場合、メンバ変数を特定のメモリ領域に 割り当てることはしません。 メンバ変数には、構造体の先頭アドレスからメンバ変数への差分 (オフセット)のみ割り当てます。
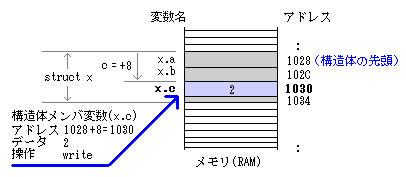
実際にアクセスするときは、上記のように 構造体の先頭アドレス(1028)に、メンバ変数への差分(+8) を足したアドレス(1030)のメモリをアクセスします。 (ちなみに、1028+8=1030 は、16進数の計算なので、 間違いではありません。)
このように、わざわざ加算しているのは、 構造体へのポインタ(先頭アドレス)が どのアドレス値で渡されたとしても、 正しく動作できるようにするためです。 つまり、すべてのメンバ変数のアドレスを渡さなくても 構造体の先頭アドレスのみ渡せば すべてのメンバ変数にアクセスができるということです。
構造体のアクセスを、*(p + m) で表現するとしましょう。
ただし、p は構造体の先頭アドレス、m は構造体の先頭から
メンバ変数への差分定数(オフセット、ディスプレースメント)です。
* は、アドレスからメモリに変換する演算子です。
この式は、ローカル変数にアクセスするときも使われます。 ローカル変数 int a; があるとしましょう。 ローカル変数は、どのタイミングで呼ばれても大丈夫なように、 また再起呼び出しができるように、スタックに積まれます。 (一部はレジスタに割り当てられますが、ここでは除外します)。 さて、実際に変数にアクセスするときは、どうしているのでしょうか。 *(p + m) における p がスタックポインタ、m がそれぞれの ローカル変数に割り当てられた値です。
また、グローバル変数にアクセスする、 コンパイルしたオブジェクトファイルを 再コンパイルしなくて済むように、 グローバル変数も *(p + m) が使われます。
このように、*(p + m) を使うことはよくあるので CPU は古くから、この演算の回路を持っています。 また、最近は *p の演算も *(p + 0) で行うことで 回路を減らすようにしているので、*p の方が *(p + m) よりも高速であるとは限らなくなっています。 つまり、構造体は加算を行うので普通の変数を使うより 遅いということはありません。 構造体を使ったほうがメリットを 得られるときは、積極的に使ったほうがいいでしょう。
構造体の設計方法は奥が深い構造体は、変数をたくさん作れることや、引数を少なくできる というメリットがあることを述べましたが、 実際に構造体を設計するときは、 それらを検討項目とすることはありません。 実際は、データベースの設計方法や、オブジェクト指向の 設計方法に従って設計していき、その結果として 変数をたくさん作れたり、引数を少なくできるようになります。 その設計方法については、簡単に説明できないので、 またいつか、シリーズを組んで行うことにしたいと思います。
| ← Prev (05) |