 ランダム・アクセス・記憶装置
ランダム・アクセス・記憶装置| ← Prev (03) |
これまでは、どの順番でプログラムを実行していくか、 いわばプロセスの話をしてきましたが、今回は データ、つまり変数についてどのように進化していったかを 説明します。
ランダム・アクセス・記憶装置A という名前の変数があり、2 という値(データ)が格納されている場合を 考えてみましょう。BASIC では、次のように書きます。
A = 2 |
そのままですね。
さて、コンピュータは、これをどのように記憶しているのでしょうか。
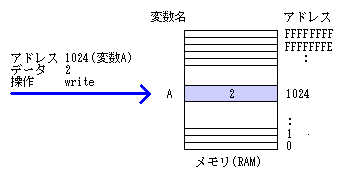
コンピュータは、RAM(Random Access Memory) と呼ばれる 記憶装置に値を記録しています。 初期の RAM は、1KB とか多くて 16KB でした。 今では、単位が違っていて、256MB とかあたりまえになりつつあります。 そのうち 1GB メモリなんて出てくるでしょう。 メモリには、それぞれの記憶領域に対して番地(アドレス)が 割り当てられており、そのアドレスを頼りに特定のデータを 読み込んだり書き込んだりします。 郵便屋さんが郵便物をとどけられるのも、土地に住所が決められていて、 郵便物に住所が書いてあるからです。 住所を英語で言うとアドレス(address)ですから、そのままですね。 この原理は、昔と比べて桁違いに容量が多くなっても同じです。
RAM は Random Access Memory の略でして、訳すと 「適当な位置からデータをやり取りする記憶装置」となります。 この意味からすると、別に半導体である必要はないので、 ハードディスクでも RAM と呼べなくも無いですけど、 それは語源でしかないですから。 RAM の意味は、読み書きできる半導体の記憶装置です。 そういえば、「記録」装置と言わずに、「記憶」装置と 擬人化しているのは何故でしょうね?
本題から離れてしまいました。 本題は、ランダム(random) です。 ランダムアクセス、つまり、適当な位置からデータをやり取りできると わざわざ言っているわけですから、 逆に、適当な位置からやり取りできないものもあるのでしょうか。 そのとおり、あります。テープがそうです。 テープは、データが並んでいるだけで、それぞれの 記憶領域に対してアドレスが割り当てられていません。 このため、途中からデータを取ろうにもアドレスが無いので、 取ることができません。いや、音楽テープを途中まで巻いて 再生できるように、取ろうと思えば取ることもできますが、 アドレスに基づいた正確な位置を特定して、特定のデータを 取ることはできません。 それでもテープという記憶装置が存在するのは、 バックアップに適しているためです。 バックアップに使われるデータは、 1つの大きなデータであり、 ランダムアクセスする必要が少ないためです。 ランダムアクセスできる高価な記憶装置よりも、 安価なテープが使われます。
一方、プログラムで必要になるデータは、それぞれが識別できる 小さなデータです。 よって、それぞれのデータに、ランダムにアクセスできる 必要があります。 それに適しているのが半導体の記憶装置、RAM です。 どのアドレスにも高速にアクセスすることが出来ます。
また、ディスクもランダムにアクセスできる記憶装置です。 ここで、ディスクが出てきましたが、実は、変数の値が ハードディスク(HD)に格納されることもあるのです。 めったに参照されない変数は、RAM から HD に いったん置かれ、参照が要求されたら RAM に戻すように Windows などの OS が自動的に管理してくれています。 そのため、パソコンに搭載されている RAM のサイズより 大きいプログラムや一時データが同時に起動できるのです。 よく、大きいデータを処理しようとすると、ハードディスクが ガリガリうるさくなりますが、これは OS が HD と RAM の間でデータを退避したり戻したりしているためです。 これを、スワップしていると言います。 その HD の領域は、スワップ領域と呼ばれます。 プログラマがプログラミングするときは、 スワップ領域に対して特に意識する必要はありません。
変数名を識別子というのはなぜか前の節では、何げに A=2 と書きましたが、A という変数名は、 私が適当に付けたものです。 プログラミング言語のルールから見れば、 変数名は、(アルファベットなら)どんな名前を つけても構いまわないことになっていますから、 A でなくても、B でも X でも、はたまた nikuman でも構いません。
しかし、注意しなければならないのが、 変数に格納したときの変数名と、 変数に格納された値を参照するときの変数名が、 同じでなければならないことです。 つまり、A=2 のように変数 A に格納したら 変数名 A で参照しなければならないということです。 あたりまえですね。 あたりまえすぎてヘソで茶を沸かしてしまうぐらいです。
しかし、これこそ最も多いプログラムのバグの原因なのです。 格納する変数名を A, B, C, D,... と適当に付けてしまったがために、 はて、C はどういう値が入っていたのか? D という変数名は使っていたっけ? という混乱状態に陥り、バグを生み出す条件が整ってしまい、 バグをプログラムに埋め込むことになります。 ですから、なるべく、わかりやすい変数名を 付けるようにすると言われるのですね。 今回は、いかにバグの少ないプログラムを作るかという 話ではないので、わかりやすい変数名をどうして付けたらいいのか、 という話はいつかすることにしておきましょう。 名前のつけ方は、非常に奥の深いものでして、 このコラム1回分、いや何回かかるかわかりませんし。
ここで言いたかったことは、同じ変数名は同じ変数に、 違う変数名は違う変数に対応しているということです。 つまり、変数名は、別の変数を区別したり、 同一の変数であると特定したりと、 まさに、識別するために使われています。 だから、C 言語などでは、変数名を識別子と呼びます。
少し別の見方をしてみましょうか。 変数は RAM の中に格納されていて、その RAM の中には、 1つ1つアドレスが振られているということでしたから、 こう言うことも出来ます。 『同じ変数名は同じアドレスに、違う変数名は違うアドレスに 対応している』。 また、RAM の特定の領域にアドレスを付けたことと、 特定の領域に変数名を付けたことは同じ行為だから、 ある意味、『変数名とアドレスは同じものだ』 と言うことも出来るでしょう。
名前の重複に気をつけろランダムアクセスできる記憶装置には、それぞれの 記憶領域に対して0番から FFFF(16進数)のように、 数値のアドレスが割り当てられています。 0番から順番に割り当てられているので、 複数の記憶領域に同じアドレスが割り当てられることは ありません。 もし、同じアドレスを割り当ててしまうと、 どの記憶領域をアクセスすればいいのか わからなくなってしまい、エラーになります。
記憶領域に限らず、 社員に対して社員番号を付けたり、 商品に対して商品番号を付けたりと、 何かに番号を付けることは、よくあります。 しかし、なぜ番号を付けるのでしょうか。 わざわざ番号を付けなくても、 社員にも商品にも名前がついているので、 識別することは出来るはずです。 同じ名前があったとしても、 漢字まで同姓同名の人は滅多にいないですし、 たとえいたとしても、何年生まれのだれだれさん のように、情報を追加していけば 最終的には識別できます。
それでも、番号をつけるのは、 あらかじめ唯一の番号を付けておくことで、 番号だけから、その人やそのものを特定できるように するためです。 「山田さん」だけ言われても、もしかすると 「どの山田さん?」といわれることがよくありますが、 「会員番号 0012 の人」、と言えば簡単かつ確実に その人を特定することが出来ます。 この仕組みを利用したのが、国民一人一人に 番号を付ける制度です。 個人データが悪用される問題が残っていますが、 番号を付けるねらいは、そこにあります。
プログラムの変数も、 あらかじめ唯一の変数名を付けることで、 変数を特定する方式が採用されています。 しかし、番号と異なり、名前は0番から順番に 付けられるものではありません。 唯一の名前にするためには、すでに使われているか 一覧をチェックしなければなりません。
プログラミングではありませんが、 その最もよく表している例が、 インターネットの URL アドレスです。 インターネットでは、IP アドレスと呼ばれる 4つの数値のアドレスを、ワークステーションや プロバイダのマシンに付けているために 世界中の任意のコンピュータにアクセスができます。 DNS(Domain Name Searvice)が URL アドレスを IP アドレスに変えています。 つまり、コンピュータに、2つのアドレスが 付けられていることになります。 このどちらのアドレスも、同じものがないように 管理されています。社内(イントラネット)で ネットワークを構築しているところで働いている人なら、 IP アドレスを間違えて入力して、コンピュータに 警告を受けたことがあるかと思いますが、 これは、コンピュータを識別できなくなってしまうためです。 URL アドレスのドメインネームは、 日本では JPNIC が管理しています。 専門機関が必要になるほど、名前の管理は大変なのです。
初期のプログラミング言語では、変数名などの 名前の唯一性に関する機能は、ほとんどありませんでした。 そのため、変数名が使われているか手動でチェック しなければなりませんでした。
その対策として、あるソフトウェア会社では、 変数名を番号に制限しているところがあります。 確かに、名前よりは簡単に唯一性を維持することが 出来るでしょうが、プログラムの読みにくさは劣悪です。 最新のプログラミング言語では、 名前の重複にあまり気にしなくても、 たとえ重複したとしても、 名前の唯一性を簡単に確保できる機能が 備わっています。 そのへんの進化の過程を次回から説明していきます。
| ← Prev (03) |