 スパゲティ・プログラムはおいしくない
スパゲティ・プログラムはおいしくない| ← Prev (01) |
前回は、古典的なプログラミング言語の特徴であった、行番号のある プログラミング言語について説明しました。 今回は、行番号を無くすためにどのような手段や考え方を プログラミング言語に取り入れたのかを説明し、 プロセスの記述の仕方について考えてみたいと思います。
スパゲティ・プログラムはおいしくない昔のプログラマーたちは、見にくいプログラムのことを 『スパゲッティ・プログラム』と呼んでいました。 スパゲティは麺が複雑に絡み合うことでソースをつかまえて 麺とソースのハーモニーを生み出していますが、 プログラムが複雑に絡み合っていると読みにくくなります。
ここでスパゲティ・プログラムの例を挙げてみます。 効果をわかりやすくするために行番号のある BASIC を使ってみます。
10 INPUT "input =", S 'ユーザが S に値を入れる 20 GOTO 50 '50 行へ飛ぶ 30 PRINT "answer =", A '結果 A を表示する 40 END 'プログラム終了 50 A = 0 60 IF S >= 10 THEN 100 'S が 10 以上なら 100行へジャンプ 70 IF S < 5 THEN 130 80 A = 1 90 GOTO 130 100 A = 2 110 IF S > 14 THEN 130 120 A = 3 130 GOTO 30 |
さて、上のプログラムを見て S にどのような値を入れると A が
どのような値になるのかすぐにわかるでしょうか?
少なくとも、プログラムがどのように実行されていくかを 順番にたどっていかなければわからないはずです。 まず 10 行でユーザから入力して 20 行でいきなり 50 行へ 飛んでいます。なぜ飛ぶのだ?と言われるかもしれませんが、 これは、ユーザインターフェイスの部分(10行〜40行)と、 計算をする部分(50行〜130行)を分けた結果です。 こう聞けば、なるほど、このプログラムを作った人も いろいろ考えているんだな、と思うかもしれませんが、 初めてプログラムを見る人にとっては、そんなこと 知ったことではありません。 これはスパゲティプログラムじゃないのか、と言われても 仕方ありません。
さて、計算をする部分(50行〜130行)では、IF 文が たくさんあって非常に複雑です。 はじめに 50行で A = 0 としています。 0 を代入するのは、初期値を 0 として後で何か計算するときの パターンなので、このプログラムもそうしているのかと 予想するでしょうね。(期待通りその予想は外れますが)
60行ではユーザの入力した値 S を判定して 100行にジャンプしています。 また、70行では別の判定式によって別のところ 130行ににジャンプしています。 それぞれ、判定式がどういうのか理解した後で、その条件が合ったときに どうするかについては、100行や 130行を探さなければなりません。 幸いプログラムは 10行から順番に大きくなっていますから 100行がどこか探すことにそれほど苦労はありませんけど、 探している間に判定式を忘れてしまう可能性が無いわけではありません。 人間は同時に2つのことを考えられませんからね。
80 行でようやく IF 文から逃れられています。 さてここを通るのはどういうケースなのでしょうか? それはすぐ上の IF 文からわかります。 IF 文の条件式を両方とも満たさなかったときですね。 しかし、満たさないとき、というのはちょっと混乱しますね。
計算をする部分(50行〜130行)をしばらく追っていくと 実は単純なことをやっているんだということが だんだん見えてくると思います。 それでは答えです。
| S | A |
|---|---|
| 〜4 | 0 |
| 5〜9 | 1 |
| 10〜14 | 2 |
| 15〜 | 3 |
さんざんプログラムを追った結果、わかったのが、 S の値がどの範囲にあるかによって A の値を決めていただけ、 ということです。
50 行では A = 0 の初期値を与えていたわけではなく、 たまたま IF 文で、A に代入しない行を通らないときの A の値 だったわけです。
上では表を使うことでわかりやすく答えを書くことができましたが、 プログラミング言語でもなんとかできないのでしょうか? 日本語という言語でも次のようにわかりやすく書くことができるのに。
いかにジャンプらしく見えなくするか実は、BASIC でも、 次のようにわかりやすく書くことはできます。
10 INPUT "input =", S 'ユーザが S に値を入れる 20 IF A < 5 THEN A = 0 30 IF A >= 5 AND A < 10 THEN A = 1 40 IF A >= 10 AND A < 15 THEN A = 2 50 IF A >= 15 THEN A = 3 60 PRINT "answer =", A '結果 A を表示する 70 END 'プログラム終了 |
ではなぜこちらのプログラムは読みやすいのでしょうか。 それは、 ダイクストラ(Edsger Wybe Dijkstra) という偉い人が提唱したプログラミング技法 『構造化プログラミング』に従っているためです。 ダイクストラは、どんなプログラムの流れも順次、選択、反復の3つ (3大制御構造)で構成されているから、 それらに制限すべきだと主張しています。 つまり、最も融通が利く代わりにスパゲティの元となる 『ジャンプ』を使うな、といっているわけです。
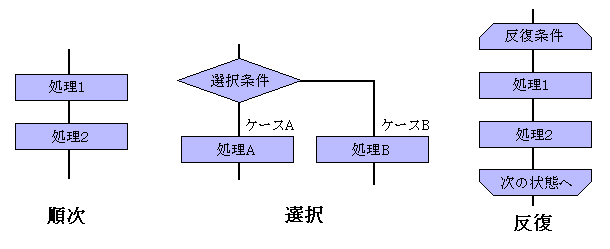
わかりやすく書いた2つ目のプログラムは、 IF 文の条件分岐を選択に変えたためにわかりやすくなったのです。 分岐と選択の違いは微妙なので説明が難しいのですが、 一言で言えば、分岐はプロセス(処理の順番)の流れに注目しているのに対し、 選択は条件とそれに対する内容との対応関係に注目しています。 わかりにくいプログラムでは、IF 文で満たした内容が ジャンプ先に書かれているために、 プロセスの流れとしては合っています。 しかし、ジャンプしているということは、 プログラムの位置が離れているということなので、 条件とそれに対する内容の対応関係が見えにくくなっています。
実は、BASIC 言語は3大制御構造を記述できる能力を持っていますが、 あまり実用的ではありませんでした。 その BASIC 言語の仕様上の限界によって、 どうしてもジャンプせざるを得ない状況があったのです。
それは、「IF 文の条件式を満たしたときに 実行する内容を記述できる量は1行以内でなければならない」 という限界です。そのため、条件を満たすときの内容を 記述する代わりに、条件を満たさないときにどこかへジャンプ させてしまわなければならないのです。
もう1つ、反復を記述する FOR 文があります。
10 FOR I=1 TO 4 ' I に 1, 2, 3, 4 と代入しながら NEXT の前まで繰り返す 20 A = A + 1 30 NEXT ' FOR 文の終わり |
そのうち、ダイクストラの主張を満たす 『構造化プログラミング言語』とよばれる言語が次々と登場しました。 pascal や C言語などです。従来からある言語を構造化した、 Fortran90 や 構造化 COBOL も登場しました。
そして、ついに構造化 BASIC が現れました。
初期の構造化 BASIC では次のように記述しました。
10 IF S > 10 THEN ' S > 10 なら以下を実行、そうでないなら ELSE(40行)へ 20 A = A + 1 30 B = B + 1 40 ELSE ' S > 10 でないときに以下を実行する 50 A = A + 2 60 B = B + 2 70 END IF ' S > 10 でもそうでないときも以下を実行する |
まだ、行番号がついていますが、すぐに不要であることに気づき、 行番号はなくなりました。また、条件を満たすときに実行する部分と 満たさないときに実行する部分が見てすぐにわかるように インデントする(行頭の空白に段差をつける)ようになりました。
IF S > 10 THEN A = A + 1 'S > 10 のときに実行 B = B + 1 'S > 10 のときに実行 ELSE A = A + 2 'S > 10 でないときに実行 B = B + 2 'S > 10 でないときに実行 END IF |
現在使われているプログラミング言語は、ほぼすべて 3大制御構造を記述できる能力を充分に持っています。 さらに C 言語では、 制御構造によるブロック構造を中括弧 '{', '}' で表現することにより、ビジュアル的にわかりやすくしています。
if ( s > 10 ) {
a = a + 1
b = b + 1
}
else {
a = a + 2
b = b + 2
}
|
このように現在では、プログラミング言語自体で3大制御構造に制限していますから、
どんな初心者でもスパゲティ・プログラムを生み出すことはありません。
構造化プログラミングって何?と言う人でも自然に
構造化プログラミングになっているわけです。
スパゲティ・プログラムや、構造化プログラミングという言葉は、
もう過去のものなのかもしれません。
注:構造化プログラミングにもいろいろな定義があって、 このページでは、プロセス(処理順序)の構造化のみを 扱っています。データを構造化する考え方もありますが、 それとは区別してください。
それでもジャンプは潜んでいる構造化プログラミングに従った読みやすいプログラムであっても ジャンプの概念はまだ潜んでいます。
C 言語は、構造化プログラミング言語と言っておきながら、
break, continue, goto, return がありますし、
Visual Basic では Exit For などがあります。
これらは、共通して『中断』という制御構造になっています。
中断の特徴は、反復や関数などのブロック(中括弧)から
抜けることなので、この先を実行しないという分岐に
相当します。選択ではないので問題がありそうですが、
反復条件(の否定条件)にも相当するので
それほど問題ではなくなっています。
これに注目すれば、break 文の条件式を
反復条件を記述するところに記述したほうがいいこともあります。
whlie ( i = 0; i < max; i++ ) {
if ( x[i] == -1 ) break;
a = i + j;
}
| または |
for ( i = 0; x[i] != -1 && i < max; i++ ) {
a = i + j;
}
|
構造化プログラミングは goto レスプログラミングと言われました。 文字通りに解釈すれば goto 文は使用しないということですが、 次のように中断であれば問題ないでしょう。
for ( i = 0; i < 5; i++ ) {
a ++;
for ( j = 0; j < 5; j++ ) {
a = i + j;
if ( a > 20 ) goto exit_for; /* ラベル名にも親切心を */
}
}
exit_for:;
|
「goto は使用しない」という文字通りの解釈した場合、 次のように見にくいプログラムになることがあるので 注意してください。
for ( i = 0; i < 5; i++ ) {
a ++;
for ( j = 0; j < 5; j++ ) {
a = i + j;
if ( a > 20 ) break;
}
if ( a > 20 ) break; /* 反復条件の二重記述 */
}
| または |
for ( i = 0; i < 5; i++ ) {
if ( a <= 20 ) {
a ++;
for ( j = 0; j < 5; j++ ) {
if ( a <= 20 ) /* 反復条件の二重記述 */
a = i + j;
}
}
}
|
他にもジャンプの概念があるのに意外に気づいていないのが
あります。それは、関数呼び出しです。よく考えれば
まさしくジャンプしているのですが、関数名が関数の内容を
見事に抽象化しているので気づかないことが多いです。
ジャンプの不都合は、ジャンプ先を探さなければならない
ということですが、関数の内容もまさしく探さなければなりません。
このへんについては、次回こうご期待ということにします。
| ← Prev (01) |